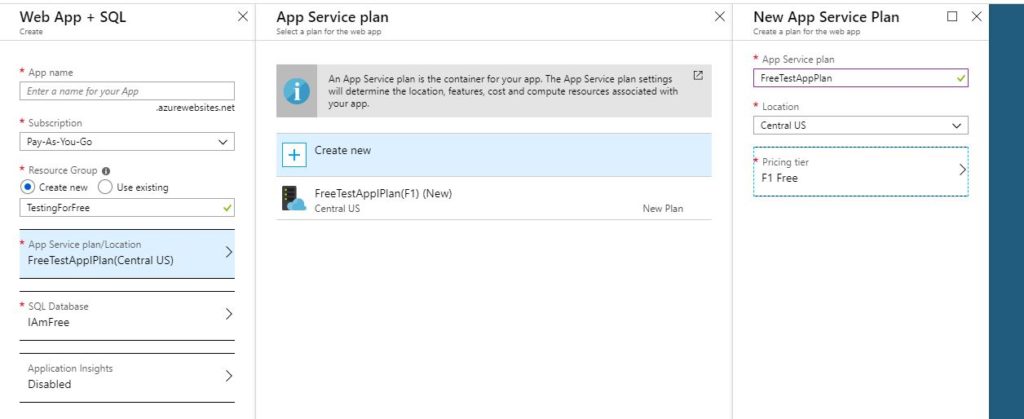
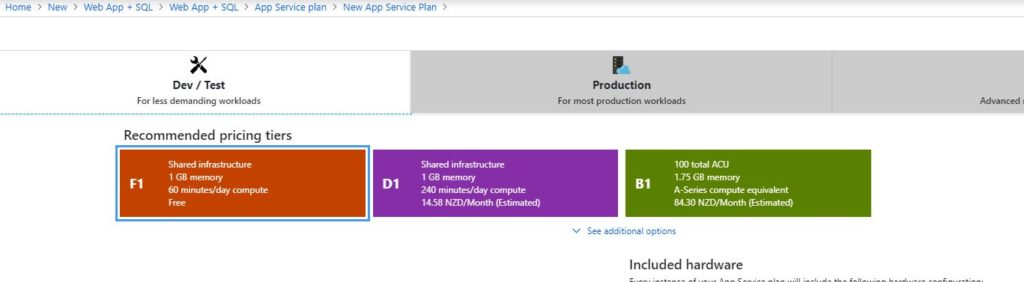
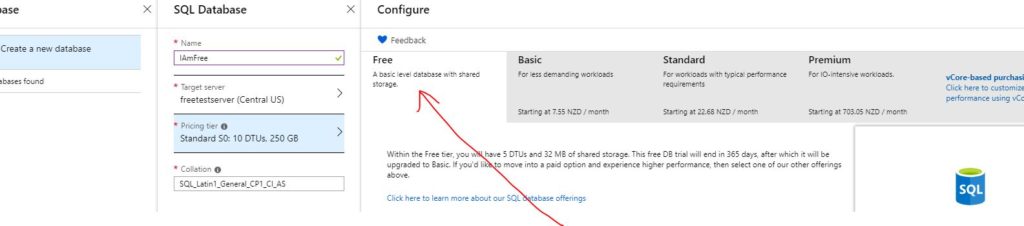
2019 has gotten off to a very busy start on the work front, but on the personal front it has been more of the same. I’ve just been putting one foot infront of the other, and I’ve been doing it alot. As a result I’ve dropped 10% of my body weight in the last 3 months.
Back in October 2018 I had a couple of health issues. The most obvious was a back injury which cost me a number of days off work and is still troubling me today when I move in the wrong way. Less obvious was a brief chest pain I experienced which I found a bit scary. My mother has suffered multiple heart attacks and my Grandfather died from one. While this issue was not a heart attack, it was scary. I knew I was overweight and working in IT I live a lifestyle which is mostly sedentary.
But while I wasn’t moving much, things were certainly very busy at work. Quite simply I felt that I didn’t have time to fit exercise into my life. I kept thinking “You can start getting fit when things aren’t so crazy” or “You can work on your health when this project is out of the way”. The only problem is, things are always crazy, and finishing one project just means you’ll have another one take it’s place.
So I took some advice from the Arnold Schwarzenegger when he was asked how he fit everything in. “Sleep faster”. I got a fitbit and resolved to getting up at 5 o’clock each morning and walking for a couple of hours. I still can’t run because it jars my back, but if I can walk, I walk. After a while walking every morning a few of those fitbit challenges seemed within reach and I found myself walking in the evenings at night. It’s a great way to unwind, get exercise and fresh air, and as a nice side effect I have slept very soundly since I started doing this.
Looking back at my history the first day I logged steps was November 21st when I was 98.8kg. Today I dropped under 90kg for the first time, weighing in at 89.6kg. That means dropping a kg roughly every 9 days, which was a bit slower than the 1 per week I was targeting, but still something I’m pretty happy about.
Why is this on a blog which is mostly technical and work related? Quite simply I’ve come to realize that everything starts with looking after yourself. I encourage everyone else to challenge their belief about how much free time they have to fit exercise into your schedule. My perspective has been flipped on its head and now everything else needs to fit around my walking, not the other way around.