![]() At my company, we’re lucky to have a custom tool that monitors EVERYTHING happening in our SQL Server environment. But every now and then, I like to explore what’s possible using only SQL Server’s built-in features-just in case you don’t have a comprehensive monitoring suite at your disposal.
At my company, we’re lucky to have a custom tool that monitors EVERYTHING happening in our SQL Server environment. But every now and then, I like to explore what’s possible using only SQL Server’s built-in features-just in case you don’t have a comprehensive monitoring suite at your disposal.
Recently, someone made an off the cuff comment about using TSQL Tasks in Maintenance Plans to handle more complex logic that SQL Agent handled out of the box. I was briefly excited by the prospect of building improved logic flows directly into SQL Server Maintenance Plans. This months Andy Levy hosts TSQL Tuesday and asks us about how we handle SQL Agent Jobs and this seemed like a great opportunity for me to share a story about how I wasted an afternoon testing a few components I have a passing knowledge with, attempting to implement auto-healing and conditional logic flow, only to snap out of it a few hours later when I realized that I was trying to solve a problem that someone else cracked nearly 2 decades ago.
The visual workflow designer and conditional branching on success or failure in Maintenance Plans seemed like a great way to automate not just routine tasks, but also smart responses to issues as they arise. I love any opportunity to implement automatic healing into anything that is likely to alert me. Getting a message saying “A thing nearly broke last night – the problem is fixed” is so much better than getting a page to fix something that retrying or a known remediation action needs to be manually performed. So I looked into a little side by side comparison of SQL Agent vs Mainteance Plans to address a scenario where a DBA performs the same boring checks and actions when a backup fails, and how both technologies allowed for implementing retries and logic flow to handle this automatically rather than have a human intervene.
The flow for this process was good at first, but as I dug deeper, I realized that while Maintenance Plans can be powerful, you can achieve the same (and often better) results with a little creative thinking in SQL Server Agent Jobs. In fact, Agent Jobs offer even more flexibility, allowing you to mix and match different step types-T-SQL, PowerShell, SSIS packages, and more-within a single job. Let me walk you through what I learned, with some real-world examples.
Maintenance Plans: Visual Logic, Limited Flexibility
Let’s start with the Maintenance Plan approach. Here’s a screenshot of a workflow I put together to handle database backups with built-in remediation and notifications but the same ideas can apply to ETL or other processes.

- The plan tries to back up all user databases.
- If the backup succeeds, it updates a central monitoring table.
- If the backup fails, it runs some auto-remediation steps (like clearing disk space or restarting a service), then tries the backup again.
- If the second attempt succeeds it updates the central repository, and if it fails, it notifies the on-call operator.
This is a solid approach, and the visual editor makes it easy to follow the logic. But there are some limitations:
- You’re mostly limited to backup, maintenance, and T-SQL tasks.
- Complex branching or looping is awkward.
- Integrating with external scripts or tools isn’t straightforward.
Agent Jobs: The Real Powerhouse
What’s more, my inital enthusiasm around the workflows was misplaced. SQL Agent actually has success and failure branching built in also at a per step level, it’s just in most cases the failure action is to say the job failed. But it doesn’t need to be.
With Agent Jobs, you can:
- Chain as many steps as you want, each with its own success/failure logic.
- Use different step types (T-SQL, PowerShell, CmdExec, SSIS, etc.).
- Easily implement loops, retries, and advanced remediation.
- Integrate with external systems, scripts, or APIs.
Here’s a screenshot of a way of achieving a better outcome using a non-standard workflow with SQL Agent. The job again handles backups with layered remediation and targeted notifications:
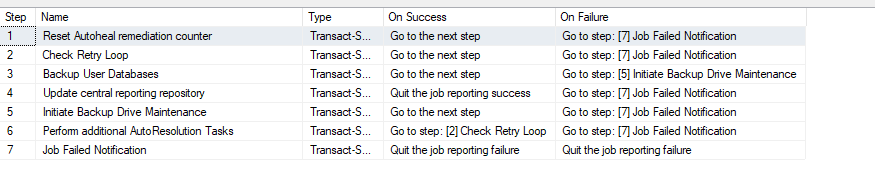
- Reset Autoheal Remediation Counter – Prepares the environment for a new backup attempt.
- Check Retry Loop – Determines if a retry is needed based on previous attempts. If the number of retries is exceeded the job generates a failure which redirects to the final step(Which is configured to alert the oncall operator)
- Backup User Databases – The main backup step.
- Update Central Reporting Repository – On successful backup the job proceeds to this step which logs the result and ends the job.
- Initiate Backup Drive Maintenance – If the backup fails, attempts to resolve likely issues.
- Perform Additional AutoResolution Tasks – Further remediation if needed. Following the completion of this step the job is redirected back to step two which increments the loop counter and retries the backup.
- Job Failed Notification – If all else fails, notifies the operator and ends the job.
Each step specifies exactly what should happen on success or failure, making the workflow both robust and transparent.
Why Agent Jobs Win
After experimenting with both approaches, I decided I hadn’t infact finally found a use for Maintenance Plans. Really the only thing they have going for them in this scenario is a nice graphic interface to visualise what is going on. That’s not to undersell the importance of a clearly identifiable workflow. The job step approach is very hard to follow if your workflows become more complicated. But here’s why I think Agent Jobs are the smarter choice for most advanced workflows:
- Multiple Step Types – You’re not limited to T-SQL or maintenance tasks. Want to run a PowerShell script, call an external API, or execute a batch file as part of your remediation? No problem.
- Granular Control – You can direct the job flow on a step-by-step basis, allowing for complex logic, conditional retries, and targeted notifications.
- Easy Integration – Agent Jobs make it simple to integrate with external monitoring systems, send custom alerts, or update centralized logging repositories.
- Maintainability – It’s easier to document, update, and troubleshoot jobs when each step is clearly defined and can be of any type you need.
Conclusion – So which should you use?
So obviously I’m leaving out some additioanl options in my side by side test. SQL Agent Jobs have auto retry built in at the per step level if you want, and the loop doesn’t have to be at the task or job step level – you can build that right into the TSQL if you like. I played around with both of these approaches for a while, trying to see if I could refine them to resolve the issues that I came up with. I really wanted that graphical format, but I also wanted the flexibility of the SQL Agent jobs. Which should I use?
When you delve into these things it’s really easy to get stuck with your blinkers on. The answer here was pretty clear. Microsoft actually built a whole tool for us to handle SQL data movement with complicated workflows and event handlers that has a flexible graphical presentation layer – and that tool is called Integration Services. Yes SSIS has some of it’s own issues but flexibility of logic flows is not one of them.
Another afternoon frittered away investigating a problem that was solved years ago….