For this months TSQL Tuesday, Joe Fleming asks us “What’s a strange or unique problem you encountered and resolved, and how did you identify the cause/resolve the issue. What was your thought process?”
For this months TSQL Tuesday, Joe Fleming asks us “What’s a strange or unique problem you encountered and resolved, and how did you identify the cause/resolve the issue. What was your thought process?”
I am taking a slightly different tangent. My problem is neither strange or unique – in fact it’s infuriatingly common and it stems from one of the most common troubleshooting techniques in IT. While asking users “Have you tried turning it off and on again?” is a common go to for tech support call handlers, it is not a great idea when the “it” you are talking about is a database server
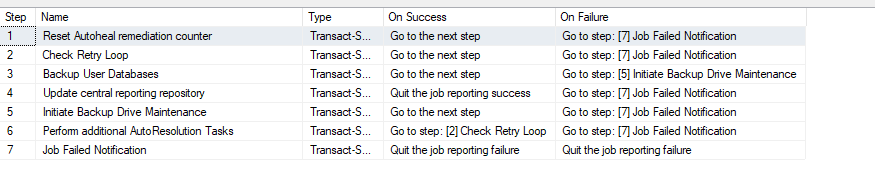
My story has happened to me in several forms over the years, but I still remember the first time it did. I had to deal with a problem where users reported a seemingly random set of job failures. Sometimes ETL jobs completed, sometimes they didn’t, sometimes they errored, sometimes they didn’t. Most systems have fairly useful logging of what is happening and SQL Server is no different.
The agent jobs that people were talking about had histories that regularly just stopped. Some had weird last run statuses of cancelled, or in one case running when there was no process attached to it. I didn’t need to look too much further at this point, but the SQL Engine error logs confirmed what I suspected – the server was being automatically started every night, and jobs were trying to run over this period.
It’s always nice to start a relationship with a new client with an easy win like this. Within about 5 minutes I could tell them what was going on, could point at the process that was doing it and had a clear path to resolve their sporadic load failure issues. Then they asked me the question “Why was this put in place?”
That’s a very difficult question to answer without having any history of the server, the jobs it has run previously and the people who had worked on it. But there was a clear clue in this case. The restart script contained a comment:
#Restart to help memory problem
Oh boy. I can only theorize at this point, but it seems like the old kneejerk to “SQL has a memory leak” response. Left to it’s own devices, SQL Server will happily grab up to the maximum amount of memory available to it (Mostly defined by the Max Server Memory setting), it’s very common for non DBA’s to see SQL using a huge chunk of memory, even when it is doing nothing right at that moment, and figure they can fix the problem by rebooting. That’s not a great response. That memory cache is a feature of SQL and what allows it to serve queries faster, not some bug or memory leak.
So in this case we could move jobs around to avoid the restart window until we’d gathered enough data to prove that the restart itself was not needed, but reflecting on it does raise the question – “Why does turning it off and turning it on again work so often?”
Here’s a subset of the reasons I can think of that a restart can work:
- Stuck processes are cleared. All those background processes that can conflict and cause blockages are cleared and start from scratch.
- Memory is cleared. Memory management is really complicated when you get into it, and over time inefficiencies in what is in memory and whether it needs to be can build up.
- Re-establishes network connections. Networks are also complicated, and restarts will often reclaim IP and register devices, resolving some of these conflicts, or at least re-registering devices.
- Updates and software glitches. There may be unapplied updates waiting on a restart to take effect. I’ve seen multiple cases where the very functionality that is supposed to avoid interrupting your workflow by holding off a restart until “a time of your choosing” actually stops it dead by breaking network connectivity or some other dependency. Likewise software bugs are not always there when you turn software on. Hopefully if they were that would be picked up in regular testing pre-release. More often a bug is triggered by a certain usecase or set of parameters. This is cleared with a restart.
In short, rebooting is a quick way to return a device to a known, clean state. It’s a universal first step because it’s fast, simple, and often effective—even if you don’t know what caused the problem in the first place.
But databases are different. For a start they are usually multi user devices, so turning them off affects every system connected to them, and turning them on again can often be a slow process. Again, this is not a bug, this is built into SQL to maintain consistency. You WANT SQL to play through the logs and bring the database to a consistent state before allowing access to the system. Consistency is only one problem that a reboot can cause, there’s a bunch of others.
- Multi-System integration – SQL itself is designed to return the database to a consistent state following a transaction, but a SQL database is not a standalone system, it is often one of many that form an intricate web of data movement. Oftentimes complex systems have a very specific order that things need to be shut down and started up in to bring back online cleanly.
- Connection Persistence – Some applications maintain a persistent connection and expect that connection to be there. One not uncommon Microsoft Enterprise Resource Planning system has the application create objects in TempDB when it first connects to the database. If the database server restarts unexpectedly these object dependencies must be known and the creation scripted to ensure application functionality.
- Application State Management – Some databases are state management engines for their application, meaning the current state is stored and the process will continue following the restart.
- High Availability implications – whatever happens on the primary server is also duplicated to secondary servers. This can lead to extended recovery periods as transactions need to be replicated to remote secondaries.
And of course the fact is that many servers are consolidated, running multiple systems, so if you restart to solve your problem, you are affecting multiple other systems at the same time. A restart is an outage on every system affected by it and may be breaching an uptime SLA on someone else’s system you aren’t even aware of.
Finally, for a user system, or even an application server, you can get away with the approach that says you just need things to work again as quickly as possible. For a database server that’s also true, but you want to understand why a problem arose in the first place too. Consult a DBA, find the root cause and fix it in a manner that you don’t see it again. Don’t just jump to “Turn it off and turn it on again.”