This week I was asked a ‘simple’ question by a client – why are the files for the primary databases smaller than the corresponding files on the log shipped secondary? Obviously it needed to have something to do with either Growth or Shrink operations, so I set up a test to find the answer.
First a recap on what log shipping does. Basically it is the process of backing up your databases and then restoring them automatically on another server, with a few bits or monitoring thrown in via management studio to make it a more manageable and versatile solution. So any question around differences between the primary and secondary databases come down to the following question “Is it a logged operation?” In this case the DBA that drew my attention to the question had already investigated shrinking the log file, and after the next backup, copy and restore the log duly shrunk on the secondary server – so it appears that shrink is logged. So that leaves growth. It’s possible that the original database had a larger autogrowth which was later adjusted, and this change wasn’t transferred to production. Let’s test.
Create the database with a stupid autogrowth setting:
CREATE DATABASE [Growtest]
ON PRIMARY
( NAME = N’Growtest’, FILENAME = N’D:\SQLData\growtest\Growtest.mdf’ , SIZE = 25600KB , FILEGROWTH = 50%)
LOG ON
( NAME = N’Growtest_log’, FILENAME = N’D:\SQLData\growtest\Growtest_log.ldf’ , SIZE = 18432KB , FILEGROWTH = 10%)
GO
And set it up for log shipping to Growtest_DR. For brevity sake I won’t include the instructions on that, but if you need them there’s a pretty good step by step guide here. Take a backup, copy and restore to make sure it’s all running properly, and check the file sizes:
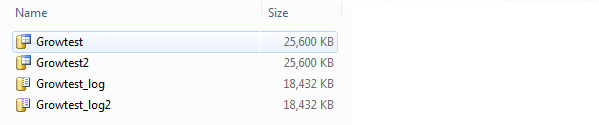
As we expect both files are the same size. Now let’s reset the autogrowth on Growtest from 50% to 10%:
ALTER DATABASE [Growtest] MODIFY FILE ( NAME = N’Growtest’, FILEGROWTH = 10%)
GO
And create a table and fill it with enough data to trigger an autogrowth:
CREATE TABLE [dbo].[SpamTable](
[randomspam] [char](8000) NOT NULL
) ON [PRIMARY]
BEGIN TRAN
DECLARE @counter INT
SET @counter = 1
WHILE (@counter <3000)
BEGIN
Set @counter=@counter+1
INSERT into dbo.spamtable values (@counter)
END
COMMIT TRAN
Then do a backup, copy, restore and check tables again:
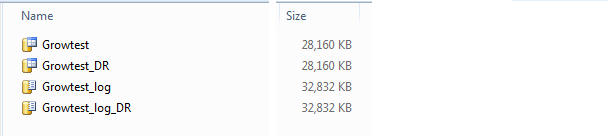
The files on DR and production are still the same size. What happens if we run the transaction but then roll it back instead of comitting it. Does SQL bother to apply and rollback the transaction, or does it just remove the transaction from the logfile?
BEGIN TRAN
DECLARE @counter INT
SET @counter = 1
WHILE (@counter <500)
BEGIN
Set @counter=@counter+1
INSERT into dbo.spamtable values (@counter)
END
ROLLBACK TRAN

After a backup, copy, restore we still have the same file sizes on DR and Prod, so there goes our growth theory. So let’s forget about what we were told when the problem was handed to us and do some shrinking. First the test that was already performed:
DBCC SHRINKFILE (N’Growtest_log’ , 0, TRUNCATEONLY)
Sure enough the log file truncation is transferred across to the DR server:

Running out of ideas, we’ll try a shrink of the data file:
DBCC SHRINKFILE (N’Growtest’ , 0, TRUNCATEONLY)
And after a backup, copy and restore:
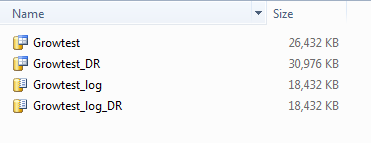
Finally, we have an answer. While autogrowth changes, and log file shrinks all appear to be logged, the shrink of the data file is not. So at some point someone has shrunk the data file on production, which is why the production data files take less space than the DR data files. So where tables are archived in production to free space, and the data file is shrunk(either with shrinkfile or shrink database), we need to be aware that this shrink is not transferred to the DR server. If we expect to reclaim that space we need to refresh the logshipping by taking a full backup from Production and restoring it over the DR database.