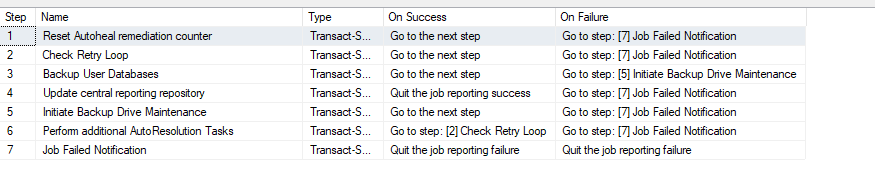
This Months TSQL Tuesday topic from John Sterrett is an interesting one because it’s something that has been occupying quite a bit of brainspace for me recently. John asks “What are you doing, or what can we do to encourage younger people to get involved in the SQL community while increasing the number of younger speakers?”. It’s also Wednesday here in NZ, and a week late – but the topic is important enough to discuss even if I’m late tot he party.
I have a big scary number birthday coming up in November, but I’m also aware of a transition in my work life from “Building a CV” to “Building a legacy”. Legacy seems like a strong word, but I am spending increasing ammount of time thinking about the guy who has to look after things after me. That is in my own job role, and in my client environments, and, as is important to this topic – within the SQL community.
I have now been speaking at SQL events for around 15 years. I am still staggered by the depth of knowledge of those around me who give their time and in most cases not insignificant expense to make themselves available for these (mostly) free training events. I am no less in awe of the amazing things some of these speakers are doing in the world today than I was 15 years ago. And I do wonder if that awe is maybe one of the things that holds some of our younger speakers back.
There is a preconception that to stand in front of a room of people and talk about a technical topic you need to be some sort of guru level savant. In the tech world we accumulate knowledge so it takes quite a serious amount of self confidence to make that first step and put yourself in front of a group of people, many of whom will be quite senior to you, and take that position of expertise.
But here’s my take – it’s actually easier to choose a topic to speak on now than it was 15 years ago. Why? Because technology is changing so fast that no-one has five years experience in most of the technologies we are using today. They only came out three years ago, or last year, or yesterday. Adding to that those very experienced guys in the room, whether presenting or listening – they have a valuable skillset which means they are very likely very busy. The ‘curious itch’ I had in my twenties and thirties remains, but there is just no way I can test and discovery all the things in all the cool technologies that are coming out. I **need** to hear stories of how people are using new technologies because the busier I get the less time I have to play with the new way of doing things. But for someone starting their career, who is more time-rich – you can tell me how you get one and what amazing results you got.
So what can we do to encourage more of this sharing? First of all I think we need to encourage the younger crowd to attend these events and importantly – stick around afterwards. There is so much that each group has to offer the other. But mostly you’ll discover that the biggest difference between you and the guys already on the speaking stage is that we are older. Usually IT draws a person with a brain that works a certain way. When I started going to SQL events I felt like I found my crowd. I could have a chat and I found that most everyone was on the same wavelength. So take advantage of the aftermatch of these events.
Secondly – I like the shorter quicker talks. It does take some time to put together a full session for a talk, so as a group maybe we can schedule short form content in with the longer form content. A 5-10 minute talk is much easier to get through than a full hour session. It’s a small window to show a single thing or feature off, rather than go through a product end to end.
And finally we need to remember the crowd. I’ve done very few talks at SQL Saturdays etc that are above 200 level. I worked out pretty early that the introductory stuff is the sweet spot. Yes there’s some experienced people in the audience, but there’s also a lot of people at the start of their story. I want those guys to be just as comfortable asking questions and making comments as the guys who have done this as long as me.